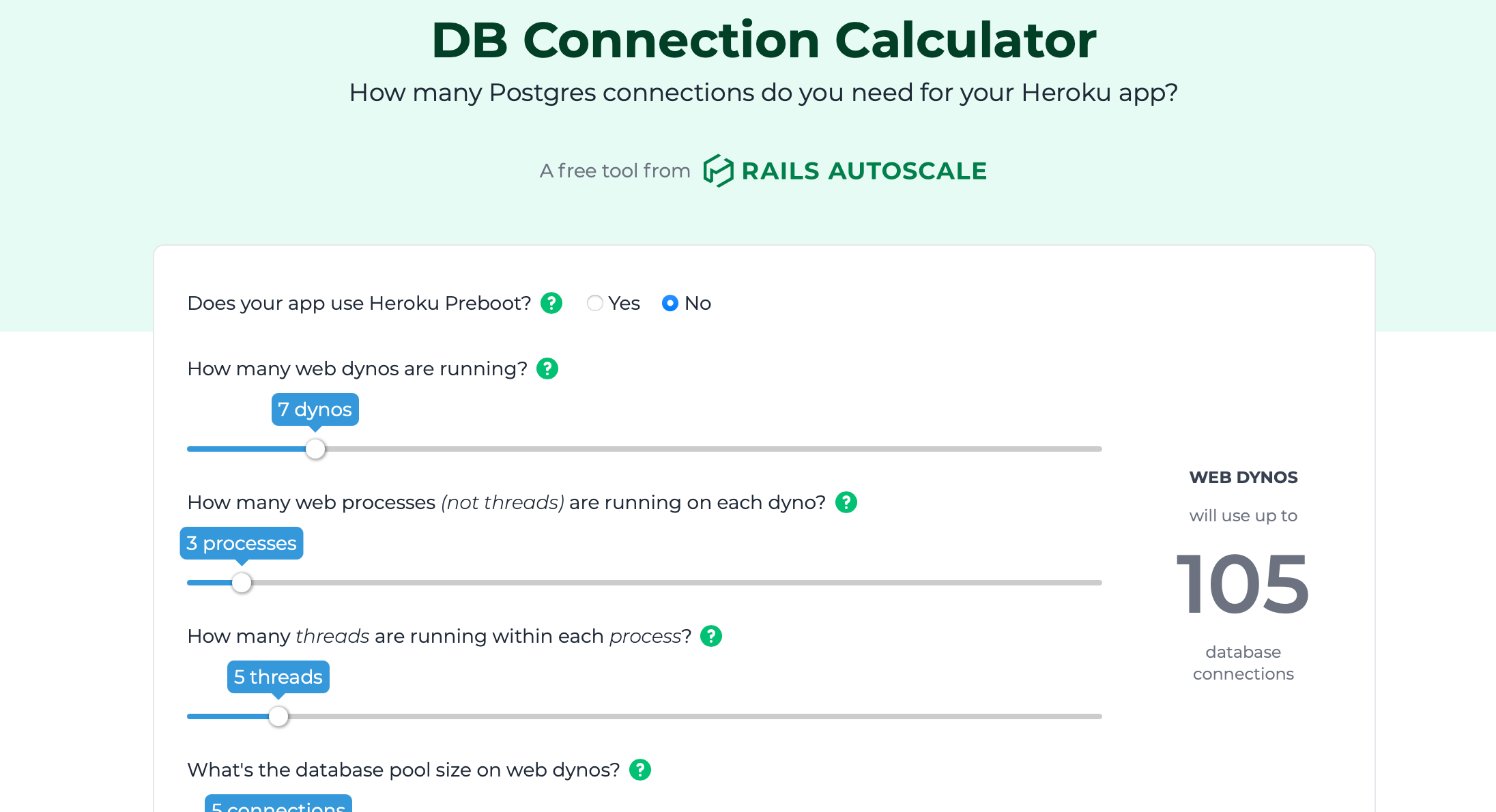
It's spring in Ohio! I'm still flying high after attending MicroConf a few weeks back, and I'm wrapping up the [largest Rails Autoscale feature](https://twitter.com/adamlogic/status/1110142400566083585) I've added since launch. Exciting times. 🔥
My emphasis this spring/summer will be on writing—on Twitter, on railsautoscale.com, and in this newsletter. So here goes...
Let's get back to Heroku and talk about Pipelines. It's recently come to my attention that many folks who are using Heroku are NOT using Pipelines. 😱
Let me be clear about my position on this: I think EVERY Heroku app should be using Pipelines. I can't think of a single scenario where it doesn't provide some benefit.
If you're unfamiliar, Heroku Pipelines are a groups of apps that share the same codebase, such as a staging and production app. Pipelines provide tooling for promoting code between these environments and automatically creating review apps for GitHub pull requests. I'm not going to talk about how to create and use Pipelines, because the docs do that very well.
Oh, did I mention Pipelines are FREE?!
The argument I hear against Pipelines is along the lines of "I'm a solo dev working on one feature at a time, so I don't need review apps". Fair enough. I'm also a solo dev on Rails Autoscale, but I still love Pipelines. Here's why...
I'm often pushing code and walking away from my computer. As a solo dev, it's important that I'm at my computer for a prod deploy in case anything goes wrong. I want prod deploys to be an intentional act, not a side effect of pushing to master. (I this goes against continuous deployment. I'm a huge fan of frequent deployment, but I'm not quite ready for continuous.)
I want prod deployments to be instant. Waiting for a build process is too much friction. Promoting staging to production using Pipelines is incredibly fast because it doesn't rebuild your app—it just copies the compiled slug.
The Pipelines UI has a lovely "compare on GitHub" button to review the exact changes that will be deployed to production.
Here's my workflow in a nutshell:
Small changes are pushed directly to master. For larger features I'll work in a branch until I'm ready to merge.
All changes on master are automatically deployed my staging app on Heroku. I use Codeship to run CI, but I do not wait for CI to pass before deploying to staging. Since it's just me, I'd rather have the speed of a faster staging deploy. If I break something on staging, I'll just fix it on the next commit. Not a big deal.
None of this impacts production. I can push complete garbage to master, and at worst I'm left with a messy commit history and a broken staging environment. I can live with this.
When I'm ready to deploy to prod, I promote staging through Slack using Heroku ChatOps. I could just as well do it through the CLI or Pipelines GUI.
That's it. My complete solo dev workflow. It's low friction, low stress, and completely enabled by Pipelines.
Thanks for reading!
BTW, if you're on Heroku and not using Pipelines, I'd love for you to reply and let me know what I've overlooked. 😊