
Mastering Heroku — Issue #3
I’ve been thinking a lot about these tweets from Nate Berkopec (author of The Complete Guide to Rails Performance):

Hi! Do you have a Rails application? Open up your code *right now* and double check to make sure that your production database pool (config/database.yml), Sidekiq concurrency, and Puma thread count are all the same number (preferably using an env variable like RAILS_MAX_THREADS).
September 7, 2018This is true if on Heroku or not: 5 for Puma/web procs, 10-25 for Sidekiq. Increase sidekiq number if your jobs do lots of HTTP calls. If mostly DB, shoot lower (10 is fine). To set this number on a per-dyno basis, add it your Procfile (e.g. "web: RAILS_MAX_THREADS=5 rails s") https://t.co/nIfgUKMgKM
September 7, 2018Multiply those considerations by your number of datastores (I use Postgres and Redis) and the number of different processes you’re running (I have 5 defined in my Procfile), and suddenly you’re juggling a lot of information.
Nate’s advice above is a great starting point, but you’ll eventually need a solid understanding of why it’s good advise and how changing any of these settings will impact your application as a whole. I find it hard to wrap my head around without some kind of visualization. Something like this tool from Manuel van Rijn, but more visual and not specific to Sidekiq and Redis. Here’s a rough sketch of what I’m imagining:
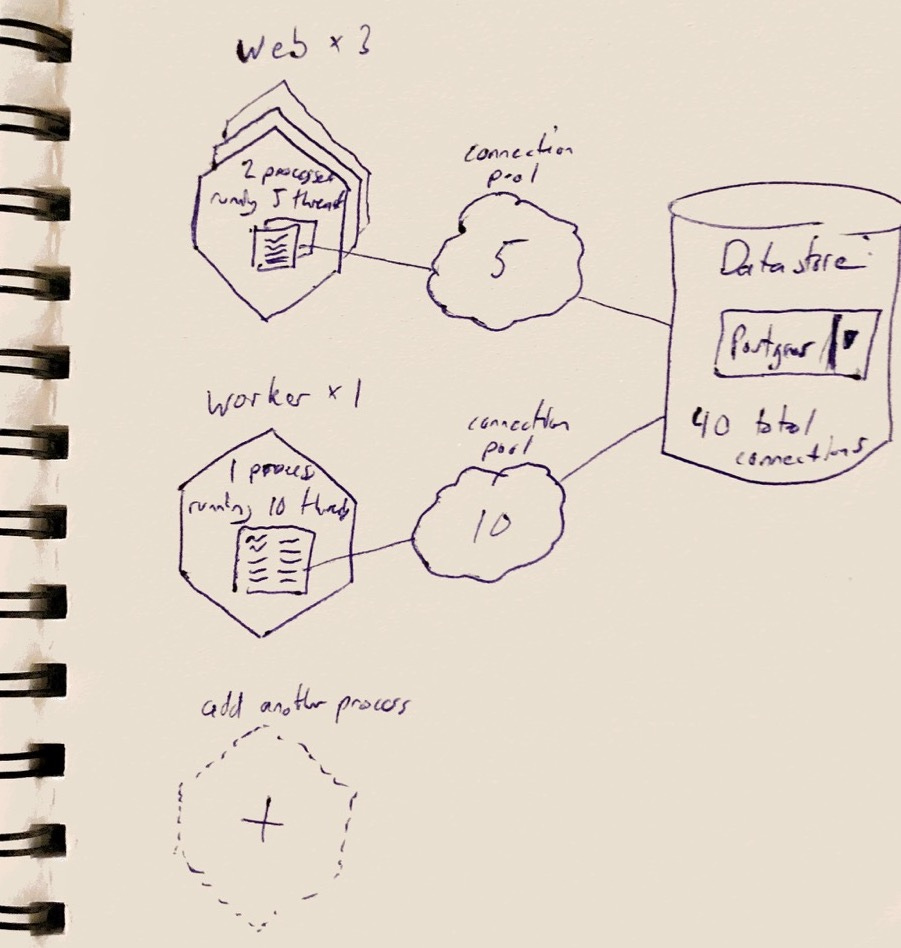
If I need to scale my app from 3 to 5 web dynos, how many extra datastore connections would I create?
What if I increase the number of processes per dyno (Puma workers, for example)?
How can I maximize the usage of my limited connections on an entry-level Postgres/Redis tier?
It could also highlight potential issues such as when a connection pool is smaller than the number of threads or when the total datastore connections exceed the current plan limit. Taking it a step further, I’d love to provide guidance on how to implement these settings, but that’s very framework-specific. I’m not sure… it’s a very rough idea right now that I thought would be fun to share.
Would you use something like this? Is it a dumb idea? Reply and let me know what you think!